
「文字化け」が起きる理由と、可能であればその直し方について、いくつかご紹介します。
文字エンコード(文字コード表)の誤判定
文字化けが起きる原因としてよくあるのが文字エンコード(文字コード表)の誤判定です。たとえば、元々のエンコードとは異なるエンコードでテキストファイルを開いてしまったり、メーラー等のプログラムで間違ったエンコードに解釈されてしまった場合などです。
この場合、よく見ると、文字化けのしかたに特徴があるので、慣れてくると元のエンコードと文字化けしたエンコードをある程度予測できることがあります。よくあるパターンを見ていきましょう。
UTF-8 を SJIS として開いてしまった場合
エンコードが UTF-8(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って SJIS として解釈すると、下図のように文字化けします。

見慣れない難しそうな漢字が多いのが特徴ですね。半角のカタカナや小文字のひらがなも混じっています。半角英数字がほぼそのまま残っているのも特徴の1つです。
元々のテキストが UTF-8 で BOM 付きである場合、SJIS として開くと下図のように先頭に「・ソ」が付きます(環境によっては違う記号に見えるかもしれません)。

UTF-8 を UTF-16 LE として開いてしまった場合
エンコードが UTF-8(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-16 LE として解釈すると、下図のように文字化けします。改行が無くなってますね。(クリック、またはタップ&ピンチアウトで拡大表示できます)
![]()
元々のテキストが UTF-8 で BOM 付きである場合、UTF-16 LE として開くと下図のようになります。
![]()
UTF-8 を日本語 EUC として開いてしまった場合
エンコードが UTF-8(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って日本語 EUC として解釈すると、下図のように文字化けします。

元々のテキストが UTF-8 で BOM 付きである場合、日本語 EUC として開くと下図のようになります。先頭に難しそうな漢字1文字が追加されてますね。

UTF-16 LE を SJIS として開いてしまった場合
エンコードが UTF-16 LE(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って SJIS として解釈すると、下図のように文字化けします。
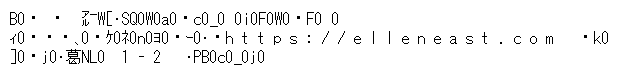
数字 0 が目立つのと、元々英数字だった文字と文字の間にスペースらしきものが入ってますね。
元々のテキストが UTF-16 LE で BOM 付きである場合、SJIS として開くと下図のようになります。

UTF-16 LE を UTF-8 として開いてしまった場合
エンコードが UTF-16 LE(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-8 として解釈すると、下図のように文字化けします。

元々のテキストが UTF-16 LE で BOM 付きである場合、UTF-8 として開くと下図のようになります。

UTF-16 LE を日本語 EUC として開いてしまった場合
エンコードが UTF-16 LE(BOM なし)の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って日本語 EUC として解釈すると、下図のように文字化けします。

SJIS として解釈した場合とよく似てますね。
元々のテキストが UTF-16 LE で BOM 付きである場合、日本語 EUC として開くと下図のようになります。
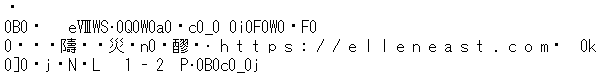
SJIS のテキストを UTF-8 として開いてしまった場合
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-8 として解釈すると、下図のように文字化けします。
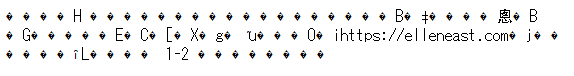
これも特徴のある化け方ですね。半角英数字はそのまま残っています。
SJIS のテキストを UTF-16 LE として開いてしまった場合
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-16 LE として解釈すると、下図のように文字化けします。(クリック、またはタップ&ピンチアウトで拡大表示できます)
![]()
難しそうな漢字が多いですね。改行が無くなっていて、元々あった半角英数字も残っていません。
SJIS のテキストを日本語 EUC として開いてしまった場合
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って日本語 EUC として解釈すると、下図のように文字化けします。

全角カタカナはほぼ残ってます。半角英数字は全て残ってますね。
日本語 EUC のテキストを UTF-8 として開いてしまった場合
エンコードが日本語 EUC の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-8 として解釈すると、下図のように文字化けします。
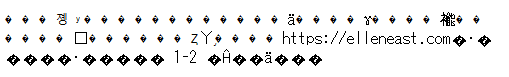
これも特徴のある化け方ですね。半角英数字はそのまま残っています。
日本語 EUC のテキストを UTF-16 LE として開いてしまった場合
エンコードが日本語 EUC の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って UTF-16 LE として解釈すると、下図のように文字化けします。(クリック、またはタップ&ピンチアウトで拡大表示できます)
![]()
改行が無くなっていて、半角英数字も残っていません。
日本語 EUC のテキストを SJIS として開いてしまった場合
エンコードが日本語 EUC の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
これを間違って SJIS として解釈すると、下図のように文字化けします。

非常に特徴的ですね。半角カタカナが多く、半角英数字は全て残ってます。
元のテキストに戻すには
文字エンコード(文字コード表)の解釈の間違いで文字化けした場合、元々の正しい文字エンコードで開きなおしてやれば良いことになります。
ただし、文字化けした状態のテキストをそのままファイルに保存して確定してしまった場合などは、元々あった情報が失われてしまったり文字コードの位置がずれてしまったりするので、一部のテキストしか復元できなかったり、全く復元できなくなったりすることがあります。
別の形式に変換されている場合
テキストの各文字がそれぞれ異なる一意の文字列に変換されたために、文字が化けているように見えることがあります。そういうケースをいくつか見ていきましょう。
文字が 16 進数に変換されている場合
たまに下記のような、奇妙な名前のファイルを見ることがあります(見たことない人のほうが多い?)。
%6587%5B57%5316%3051.txt
これはファイル名のテキストが 16 進数に変換されているファイルです(% は区切り文字と考えてください。別の記号になることもあります)。
このファイル名を復元すると「文字化け.txt」となります。
なぜこんなこと(ファイル名を 16 進数にする)をするのでしょうか?
たとえば Unicode には存在するけれど SJIS には存在しないような文字がファイル名に含まれている場合、そしてそのファイルを Unicode に対応していないシステムやアプリケーションで処理したい場合、ファイル名をそのままにしておくと処理後に文字化けしてしまったり、処理中にエラーを起こしたりする可能性があります。それを避けるために、事前にファイル名を 16 進数に変換することがあります。あるいは、使用するアプリケーションによっては、勝手に変換されてしまうこともあります。
同様の理由で、文書の中身のテキストが 16 進数に変換されることもあります。
復元するには、たとえば EmEditor を使うと、[編集]>[高度な操作]>[特殊文字を入力]で 16 進数を指定して文字を出すことができます(ただし1文字ずつ)。
処理量が多いときは、変換ツールを探すと良いかもしれません。
Base 64 にエンコードされている場合
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
このテキストが Base 64 にエンコードされると下記のようになります。
gqCC6oFIIJW2jpqJu4KvgrWCv4LhgsGCvYFCgseCpIK1guaCpIFCDQqDR4OMg5OB
RYNDgVuDWINngsyDdYONg0+BaWh0dHBzOi8vZWxsZW5lYXN0LmNvbYFqgskNCoK7
gvGCyItMjpaCqiAxLTIgjMKCoILBgr2CyA0K
復元の方法はいくつか考えられますが、たとえば、コマンドプロンプトで下記のようにして復元することができます。
certutil -decode -f [入力ファイル] [出力ファイル]
uuencode にエンコードされている場合
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
このテキストが uuencode されると下図のようになります。
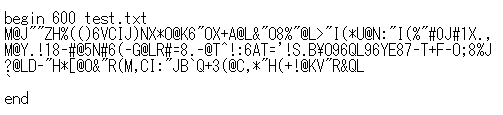
復元の方法はいくつか考えられますが、たとえば、UnxUtils を使用する場合、コマンドプロンプトで下記のようにして復元することができます。
uudecode.exe [入力ファイル]
ちなみに、出力ファイル名はエンコードされたテキストの中に含まれています。上図の例では1行目の “test.txt” が出力ファイル名になります。
エンコードが SJIS の下のようなテキストがあるとします。
あれ? 文字化けしちゃった。どうしよう。
エレン・イーストのブログ(https://elleneast.com)に
そんな記事が 1-2 個あったな
このテキストが URL エンコードされると下記のようになります。
%E3%81%82%E3%82%8C%EF%BC%9F+%E6%96%87%E5%AD%97%E5%8C%96%E3%81%91%E3%81%97%E3%81%A1%E3%82%83%E3%81%A3%E3%81%9F%E3%80%82%E3%81%A9%E3%81%86%E3%81%97%E3%82%88%E3%81%86%E3%80%82%0D%0A%E3%82%A8%E3%83%AC%E3%83%B3%E3%83%BB%E3%82%A4%E3%83%BC%E3%82%B9%E3%83%88%E3%81%AE%E3%83%96%E3%83%AD%E3%82%B0%EF%BC%88https%3A%2F%2Felleneast.com%EF%BC%89%E3%81%AB%0D%0A%E3%81%9D%E3%82%93%E3%81%AA%E8%A8%98%E4%BA%8B%E3%81%8C+1-2+%E5%80%8B%E3%81%82%E3%81%A3%E3%81%9F%E3%81%AA
復元の方法はいくつか考えられますが、たとえば、「URL エンコード 変換」のようなキーワードでネット検索すると、ブラウザ上で変換可能なサービスがたくさん見つかります。
特定の文字だけ文字化けする場合
文字エンコードは正しく変換されていてテキストのほとんどは正常なのに、特定の文字だけが文字化けする場合は、下記を確認してみてください。
変換前の文字エンコードにしか存在しない文字を使用してないか?
変換前の文字エンコード(文字コード表)には存在するけれど、変換後の文字エンコードには存在しない文字を使用してませんか?
たとえば、膨大な数の文字を使用できる Unicode に比べて、SJIS で使用できる文字は限られています。Unicode には存在するけれど SJIS には存在しない文字が使われている場合、そのテキストを SJIS に変換すると、たとえば下記のように文字化けします。

Unicode には、SJIS で使える文字に似ているけれど SJIS では使えない文字もたくさんあるので注意してください。
Unicode で使える文字を全て把握することは無理だと思いますが、SJIS で使える文字をざっと確認することは可能です。「SJIS 文字コード表」などのキーワードでネット検索してみると、SJIS で使用できる文字の一覧(文字コード表)を見ることができます。
機種依存文字を使用してないか?
機種依存文字または環境依存文字などと呼ばれる文字があります。これも大きな意味では文字コード表の違いの問題であったり、またはハードウェアの機種に依存する問題のこともあります。自分の環境では問題なく読めるテキストでも、別の人の環境では一部の文字が別の文字に置き換わってしまったり、消えてしまったりするので、厄介です。
世の中のすべての人が Unicode を使用するようになればあまり気にしなくて良い問題とも言われますが、まだ Unicode が浸透していないところもあるようなので、万全を期すのであれば機種依存文字は使わないほうが良いかもしれません。
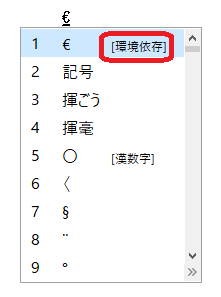
下図は、MS IME の変換候補一覧に環境依存文字が表示されているところです。「機種依存文字」というキーワードでネット検索すると、機種依存文字の一覧を確認できます。
フォントがあるか?
ほとんどの文字は指定されたフォントが見つからない場合でも、別のフォントが代替することにより表示されるので、あまり気にならないと思います。
しかし一部には代替できるフォントが存在しない文字もあり、そのような文字はフォントが見つからないと化けることがあります。
ファイル名の文字化けを防ぐには
この記事を読んでいただいた方から「ファイル名が化けてしまった」「ファイル名に英語を使えば対策になるのか?」というコメントを投稿していただきました。
結論から言うと、ファイル名の文字化けを防ぐのに一番良い方法は、おっしゃる通り「ファイル名に半角英数字のみを使用する」ことです。
ファイル名を扱うアプリケーション(FTPソフト、圧縮・解凍ツール、etc.)の中には、日本語ファイル名や Unicode のファイル名に対応していないものがあります(特に開発者が外国の方の場合)。そういったアプリケーションを使うと、日本語が混じったファイル名が文字化けすることがあります。
日本において、ファイル名に使用される文字エンコードは、SJIS または UTF-8(BOM なし)または日本語 EUC のいずれかだと考えられますが、これらの文字エンコードの間で変換が生じたとしても、半角英数字はそのまま維持されるので、ファイル名に半角英数字のみを使用しておけば、まず文字化けすることはありません。
なお、半角記号をファイル名に使いたい場合もあると思います。SJIS の半角記号(キーボードから IME 変換せずに直接入力できる記号)の一部はファイル名に使われることがありますが、 OS によっては一部の半角記号に特別な意味(役目)を持たせていてファイル名には使えないものがあり、注意が必要です(OS によって使用できる記号は異なります)。Windows で、ある記号をファイル名に使用できたとしても、たとえばそのファイルをリモートの Web サーバーにアップロードするような場合は、そのサーバーの OS でも使用可能か調べておいたほうが良いでしょう。このようなことを考えたくなければ、半角記号も使わないほうが無難です。
最近体験した文字化けの事例
最近私が実際に体験した文字化けの事例を紹介します。
アマゾンからのメールの一部が文字化けしている
アマゾンで商品を購入したあとで発送連絡のメールが届いたのですが、それが下記のように文字化けしていました。

右のほうの1字だけ文字化けしてますね。全体的には正常なのに一部分だけ文字化けしているということは、テキスト全体の文字エンコードの解釈は間違ってないということです。
では、現在の文字コードでは表現できない文字が使われているのでしょうか?現在の文字コードを調べるためにメール上で右クリックしてみると UTF-8 だということが分かりました(HTML メールだったので、HTML ソースを見て調べることもできます)。
変ですね。UTF-8(Unicode の一種)ならば、世の中の大抵の文字は表示できるはずなのに。
文字化けしている文字を探るため、化けている文字を EmEditor 上にコピペして、文字コードを調べてみました。
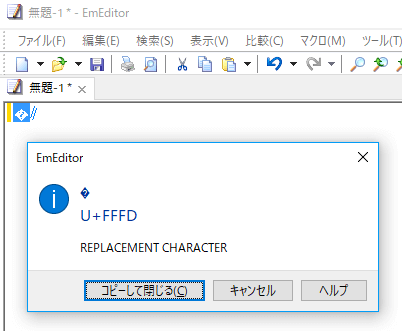
文字コードは U+FFFD(”U+” は Unicode ということです)、そして「REPLACEMENT CHARACTER」という説明が表示されています。この文字は、Unicode 上で表現できない文字があったときに元の文字を置き換えるための文字です。つまり、元の文字はもう失われていて、そのテキストが私に届いたわけです。
復元は不可能だと分かりました。
しかし本来そこに何の文字または記号があったのかが気になったので(また、文字化けの原因が気になったので)、アマゾンのチャットサポートに聞いてみました。最初は、アマゾンさんの問題・ミスだろうと思っていたのですが、サポート担当さんに調べていただくこと5~10分、原因が判明しました。
本来、その文字化けがあったところは、出品者が英数字を使用して伝票番号を入力するところだそうです。ところが出品者が(英数字以外の)使用できない文字を入力してしまったため、システムがうまく処理できなくて文字化けした、ということでした。出品者のミスだったんですね。
アマゾンさん、疑ってすみませんでした。ご丁寧に調べていただきありがとうございます。スッキリしました。


エレンさん、こんばんは。
最近、災害が国内各地で起きてしまいましたね…。大丈夫でしょうか?
文字化けでも、エンコードによって、異なる化け方?をするんですねー!
最近、文字化けで困ったと言えば、
FTPソフト(Filezila)で、ブログのバックアップをした際に、画像の名前が化けてしまいました…。
保存してしまったため、修復は腰が上がりません(笑)
末永く付き合っていこうかと思います。
初心者丸出しの質問で申し訳ないんですが、
文字化けを防ぐため、日本語を使わず、英語を使う…というのも対策になるんでしょうか?
悠々さん、こんばんは!
「災害列島 日本」と言われますが、それにしても大変な災害が続いてしまってますね。防災対策は日頃からの準備が大切ですね。
文字化けのしかたに模様のようなパターンがあるのは面白いでしょう?(笑)文字化けに遭遇した当人はそれどころじゃないでしょうけれど。^^;
ご質問ありがとうございます!おっしゃる通り、ファイル名の文字化けを防ぐ安全な方法は、「半角英数字のみを使う」ことです。
記事に「ファイル名の文字化けを防ぐには」を追加しておきました。ご参考になれば幸いです。^^